
검색결과 리스트
글
[논문 리뷰]Self-training with Noisy Student improves ImageNet classification
설정
트랙백
댓글
Self-training with Noisy Student improves ImageNet classification
2020년 CVPR 발표 논문이다. ImageNet 이미지 외에 300M의 추가 Unlabeled 이미즐 통한 Un-supervised learning을 통해 EfficientNet의 성능을 올렸다.
주요내용
ㆍ네트워크 성능

- ImageNet top-1 accuracy (한가지만 선택, top-3의 경우 3개지 선택해서 한가지라도 맞으면 성공) 88.4% 달성
- ImageNet-A (난이도 Up, Natural) top-1 accuracy 83.7% 달성
- ImageNet-C (Noisy, blurred, fogy 등 corrupted Images) 에서 corrunption error 28.3 달성
- ImageNet-P (Brightness, tilt, roate, scale 등 Perturbations이 적용된 Images) 에서 mean flip rate 12.2 달성
※ImageNet과 ImageNet-A는 정확도를 측정하기 위해서, ImageNet-C와 ImageNet-P는 일반영상이 아닌 깨지거나 비오는 영상등 악조건에서 얼마나 잘 판단할 수 있는지 robustness(강건함)을 측정
ㆍ학습 방법
Classification의 정답을 아는 (labeled) 120만개의 이미지와 (ImageNet) 추가로 정답을 모르는 (Un-labeled) 3억개의 이미지(JFT dataset)을 이용해 정확도를 높인다.
- Labeld image를 학습 한다.(이 때 학습 받는 네트워크를 Student라고 한다.)
- 학습된 네트워크로 Unlabeled image에 가짜(pseudo) label을 붙인다.(학습되는 Student 네트워크를 Pseodu 라벨을 붙이는 Teacher로 바꾼다.)
- Pseodo label과 ImageNet image를 이용해 새로운 Student 네트워크를 학습 시킨다.
- 이 과정을 반복한다.
즉 처음 진짜 label이 있는 120만개 이미지를 이용해 네트워크를 학습시키고 (Student 네트워크) 이 네트워크를 이용해 라벨이 없는 3억개의 이미지에 가짜 라벨을 붙이고, 3억 + 120만개 이미지를 이용해 다시 네트워크를 학습시키고, 학습이 완료되면 다시 가짜라벨 -> 학습 가짜라벨 ->학습 이 과정을 반복한다.
'논문 & 책 리뷰 > Deep learning' 카테고리의 다른 글
| [논문 리뷰]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2021.04.08 |
|---|---|
| Chapter 5. Machine Learning Basics (2/2) (0) | 2019.01.27 |
| Sample mean and sample variance. (0) | 2019.01.26 |
| Chapter 5. Machine Learning Basics (1/2) (0) | 2019.01.22 |
| Chapter 4. Numerical Computation (0) | 2019.01.13 |
글
[논문 리뷰]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
설정
트랙백
댓글
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
주소 : https://arxiv.org/abs/1905.11946
2019년 발표 논문이라 이미 유명한 논문이고, 많은 한글 리뷰가 존재하지만, 원래 하려던 Revisiting ResNets 논문을 리뷰 하기 위해서 먼저 리뷰한다.
Abstract
기존 Convolution Neural Networks에서 정확도를 높일 때, 우선 아키텍쳐를 만들고 Convolution의 채널이나, 깊이, 이미지의 해상도를 높이는 방식으로 계산량을 늘려서 정확도를 올리는 방식을 사용한다. 그런데 이런 채널 수 (width) / 깊이(depth) / 이미지 크기(resolution)를 어떻게 늘리는게 좋은지에 대한 연구가 없어서 효율적으로 scaling을 하는 방법을 소개한다.
더 나아가, Neural Architecture Search를 사용해 baseline 네트워크를 만들고, scaling을 수행해서 기존 ConvNet보다 높은 정확도와 효율성을 달성하는 EfficientNets라는 모델 제품군을 제안한다. EfficientNet-B7은 ImageNet top-1 accuracy 84.3%를 달성하면서 기존 ConvNet보다 8.4배 작고 6.1배 빠르다
주요 내용
ㆍ네트워크 성능

Fig. 1의 왼쪽 그래프는 네트워크의 파라미터 수 대비 성능(정확도)를 나타내고 오른쪽 그림은 네트워크 수행시간 대비 성능(정확도)를 나타낸다. 빨간선이 논문에서 제안하는 EfficientNet들이다. 사이즈가 가장 작은 B0부터 Scaling 기법을 적용해 사이즈를 키워나간 B1~B7이 기존 네트워크들 보다 더 가볍거나 빠르고 성능이 좋게 나오는 걸 보여준다.
ㆍCompund scaling
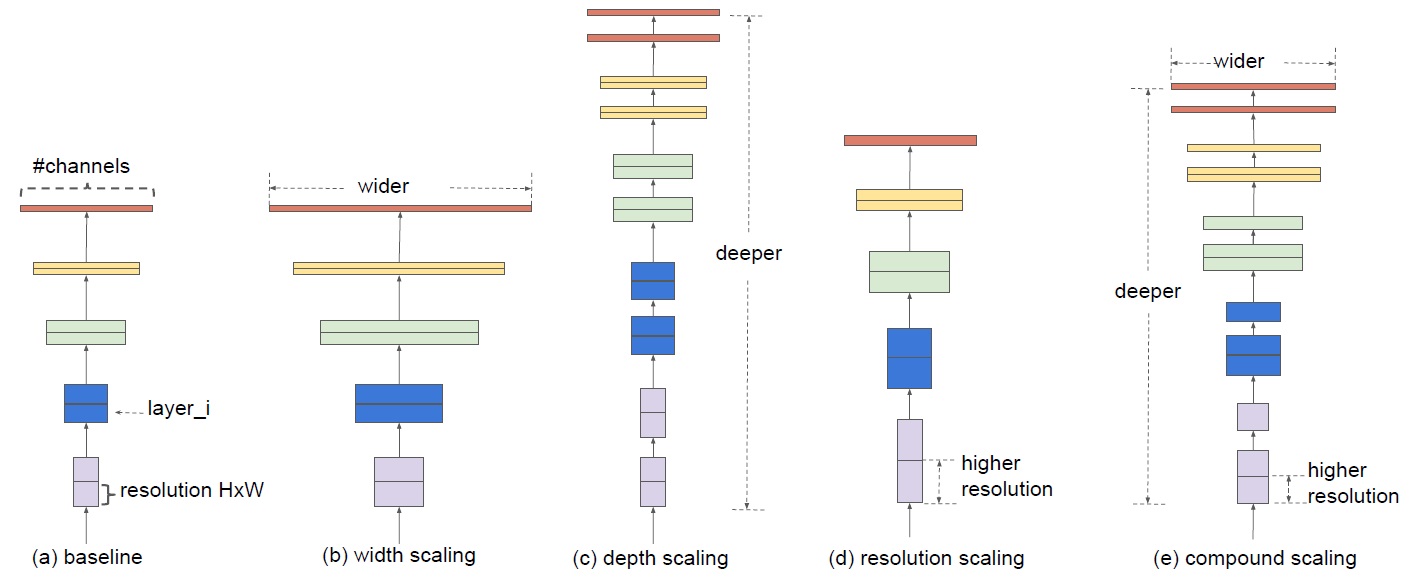
Fig.2는 다양한 scaling 방법을 보여준다. 위에서도 설명했지만 네트워크의 채널/깊이/이미지 사이즈를 늘려가는 것을 각각 width / depth / resolution scaling이라고 한다. 왜 compund scaling 인가? 아래 Fig. 3을 생각해보자

직관적으로, 이미지의 해상도가 증가할 때, Receptive Field가 증가하지 않으면 결국 더 작은 영역을 보고 판단해야 하므로 정확도가 떨어질 수 있다. Receptive Field를 키우기 위해서는 네트워크 깊이를 증가시켜야 하고, 해상도가 커진만큼 더 세밀한 패턴들을 판별하기 위해서 채널수가 증가되어야한다.
여기 까지가 주요 내용이다. Motivation은 맞는 말이지만 EfficientNet에서는이 width / depth / resolution을 어떤 조합으로 scaling 할지에 대한 고민은 좀 부족해 보인다. 이 부분은 Revisiting ResNets에서 조금 더 보충 된다.
상세 내용
ㆍCompund Model Scaling
저자가 정의한 문제는 Accuracy (정확도)를 최대로 높이면서 Memory와 FLOPS (계산량)은 어떤 목표보다 작게 하는 것이다. 즉 효율적인 네트워크는 정확도는 높고 계산량은 적은 네트워크 일텐데, 이 논문에서는 작은 네트워크 (EfficientNet-B0)에서 이 아키텍쳐를 찾고, Scaling을 통해 계산량을 늘려간다.
\[\begin{array}{*{20}{rl}} {{\rm{depth:}}}&{d = {\alpha ^\phi }}\\ {{\rm{width:}}}&{w = {\beta ^\phi }}\\ {{\rm{resolution:}}}&{r = {\gamma ^\phi }}\\ {{\rm{s}}{\rm{.t}}{\rm{.}}}&{\alpha \cdot {\beta ^2} \cdot {\gamma ^2} \approx 2}\\ {}&{\alpha \ge 1,\beta \ge 1,\gamma \ge 1} \end{array}\]
\(\alpha\), \(\beta\), \(\gamma\)는 상수이고 small gride search를 통해 찾는다. - 즉 초기 (가장 작은) 네트워크에서 실험적으로 찾는다.
\(\alpha \cdot {\beta ^2} \cdot {\gamma ^2} \approx 2\)를 설정한 이유는 FLOPS가 대략 \(2^\phi\)배로 증가하기 위해서이다. - 그렇다고 \(\phi\)가 1,2,3...이렇게 자연수로 증가하는 것은 아니고 큰 의미는 없는 것 같다.
ㆍEfficientNet Architecture
EfficientNet은 MnasNet과 같은 search space를 사용했으며, 최적화 목표를 \(ACC(m) \times {\left[ {FLOPS(m)/T} \right]^w}\)로 설정했다. 여기서 \(T\)는 목표로 하는 FLOPS이고, \(w=-0.07\)은 Accuracy와 FLOPS의 trade-off를 나타내는 하이퍼 파라미터이다. MnasNet은 Accuracy-Latency를 최적화 했는데, 본 논문에서는 Accuracy-FLOPS를 최적화 한다. (Target hardware device를 정하지 않아서)
이렇게 찾은 네트워크를 EfficientNet-B0라고 하고 구조는 MnasNet과 비슷한데, FLOPS target을 400M으로 해서 사이즈가 약간 더 크다. 이렇게 찾은 구조는 아래 표와 같다.

이 네트워크의 Main building block은 MobilNetV2, MnasNet에서 사용된 mobile inverted bottleneck MBConv 이다
EfficientNet-B0가 baseline 네트워크 이고, 이 네트워크를 Scaling 하는 방법은 아래와 같다.
- STEP1. \(\phi\)를 1로 고정시키고, \(\alpha\), \(\beta\), \(\gamma\)를 찾는다.실험 적으로 찾은 값은 EffientNet-B0에서의 값은 \(\alpha=1.2\), \(\beta=1.1\), \(\gamma=1.15\) 이다.
- STEP2. \(\alpha\), \(\beta\), \(\gamma\)를 고정시키고, \(\phi\)를 변화시키면서 EfficientNetB1~B7을 찾는다.
Revisiting ResNets에서 Claim하는 부분이 이 부분인데, 작은 네트워크에서의 \(\alpha\), \(\beta\), \(\gamma\)가 큰 네트워크에서도 동일하지 않다는 걸 보여줌 (이런 선형 관계도 아님)
Experimentals
ㆍScaling Up MobileNets and ResNets
Compound scaling 방식이 좋다는 것을 증명하기 위해서 MobileNet과 ResNet에 실험을 했다.

위 테이블을 보면 MobileNetV1과 MobileNetV2, ResNet-50에 대해 각각 depth / width / resolution / compound scaling을 적용했다. 표에서 보여주는 것 처럼 FLOPS를 유사하게 맞췄을때, Compound scaling 방법이 높은 성능을 보여주고 있다.
ㆍImageNet Results for EfficientNet

위 테이블은 EfficientNet의 성능을 보여준다. 일반적으로 EfficientNet이 다른 ConvNet보다 적은 파라미터를 가지고 FLOPS가 낮다. 특히 EfficienNet-B7은 84.3% 정확도를 달성하면서 Gpipe대비 8.4배 작다.

지연시간(latency)를 확인하기 위해서 CPU에서 실행을 했고, 위 표에서 결과를 보여주듯이 EfficientNet이 빠르다.
ㆍEfficientNet에서 scaling 비교

위 그림은 EfficientNet-B0에서 single-scaling과 compound scaling기법을 비교한 실험이다. width / depth / resolution을 단독으로 scaling 하는 것 보다 compound 방식으로 scaling하는 것이 성능이 더 좋다는 것을 보여준다.

위 그림은 왜 compound 방법이 다른 방법에 비해서 성능이 좋은지 분석 하기 위해 class activation map을 뽑아 본 것이다. 다른 맵들에 비해 중요한 영역을 잘 찾는 것을 볼 수 있다.
결론 및 느낀점
이 논문의 중요 내용은 EfficientNet 이라는 아키텍쳐 보다는 Scaling 방법에서 width / depth / resolution을 각각 사용하기 보다는 함께 사용하는 것이 좋다는 것을 증명한 것이고, 이러한 scaling에 대한 연구는 사실 시간이 매우 오래 걸리고 실험을 많이 해야 할 수 있을 것같다.
Compound 방식을 이용해 scaling해야 한다는데는 동의하지만, 논문에서 제안한대로 \(\alpha\), \(\beta\), \(\gamma\)의 관계를 설정해서 scaling하는 방식 자체는 너무 직관적이고, 실험을 많이 해봐야 하는 부분이다. 이런 부분들은 연구해서 개선할 여지가 많이 남아 있는 것 같다.
'논문 & 책 리뷰 > Deep learning' 카테고리의 다른 글
| [논문 리뷰]Self-training with Noisy Student improves ImageNet classification (0) | 2021.04.15 |
|---|---|
| Chapter 5. Machine Learning Basics (2/2) (0) | 2019.01.27 |
| Sample mean and sample variance. (0) | 2019.01.26 |
| Chapter 5. Machine Learning Basics (1/2) (0) | 2019.01.22 |
| Chapter 4. Numerical Computation (0) | 2019.01.13 |

RECENT COMMENT